 This blog is the outcome of my 4 months of internship at GoSecure. This research internship was goal oriented and I had to pick out of 5 different research projects. I selected a topic I knew little about in order to challenge myself: crawling and indexing data. Here, I will describe two internal projects that we have developed to gather all kinds of interesting and valuable data. The first project aimed at gathering data on .onion sites—known as the Darknet—while the second one focused at gathering data on sites like Pastebin, GitHub’s gists and Dumpz. Besides this blog, I will present with Olivier Bilodeau these two projects at an academic law enforcement conference later in June.
This blog is the outcome of my 4 months of internship at GoSecure. This research internship was goal oriented and I had to pick out of 5 different research projects. I selected a topic I knew little about in order to challenge myself: crawling and indexing data. Here, I will describe two internal projects that we have developed to gather all kinds of interesting and valuable data. The first project aimed at gathering data on .onion sites—known as the Darknet—while the second one focused at gathering data on sites like Pastebin, GitHub’s gists and Dumpz. Besides this blog, I will present with Olivier Bilodeau these two projects at an academic law enforcement conference later in June.
Context
These projects are meant to help our research and pentest teams. With these new tools in place, we gather and monitor all kinds of data, from the HTML pages of .onion sites to specific pasties from Pastebin, GitHub’s gists or Dumpz. With the collected data, we can contact clients or partners if suspicious data is found about them or we can use that data for future research on online malicious activities. Another use-case, for the pentest team on Red Team engagements or purposefully scoped pentests, is to leverage the data found (emails, domain names, credentials, API keys, etc.) to remotely gain access to the organization being tested. Just like a properly funded or sufficiently motivated adversary would do. Lastly, we have received requests to do so called “Darknet assessments” and so far we have accomplished them using publicly available tools. In order to evaluate how much a darknet monitoring product is worth, we wanted to try ourselves first. For all the above-mentioned reasons, the research team believed that it was worth it to invest a whole internship into these projects.
Enter GoSecure TorScraper (Darknet)
At first, we evaluated open source projects with specific characteristics in-mind: a scalable architecture (ideally based on ElasticSearch) and something not too complex to maintain. The FreshOnion Torscraper fitted the best our requirements. After some attempts at sending pull requests upstream were met without any response so, complying with the AGPL license, we forked it and improved it on our side. We fixed some bugs and added several functionalities, such as a the detection of login forms and new search features. We also improved the installation instructions to make them up to date and more approachable.
If you are interested, here is the Github project. So far, we gathered data from 4300 onion domains collecting the content of each accessible page on the domain visited. Here is a picture of the Web interface:
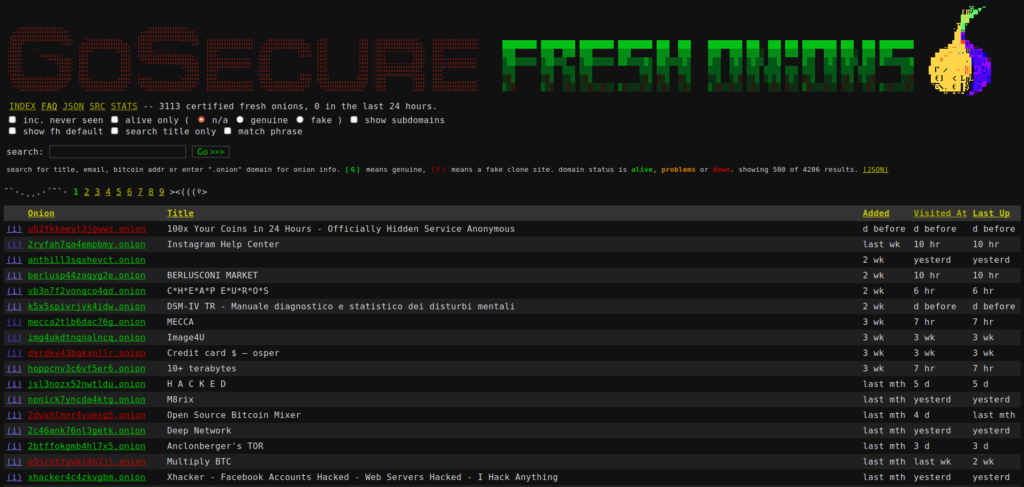
As you can see, the information is separated in tabular form where you can see the domain URL, the page’s title, the moment the domain was added, the last moment it was visited and the last time it was was seen by the crawler.
You can use the small (i) on the left side of each row to redirect to the domain’s details. As you can see, there is some structured information that allows us to pivot between .onion domains.

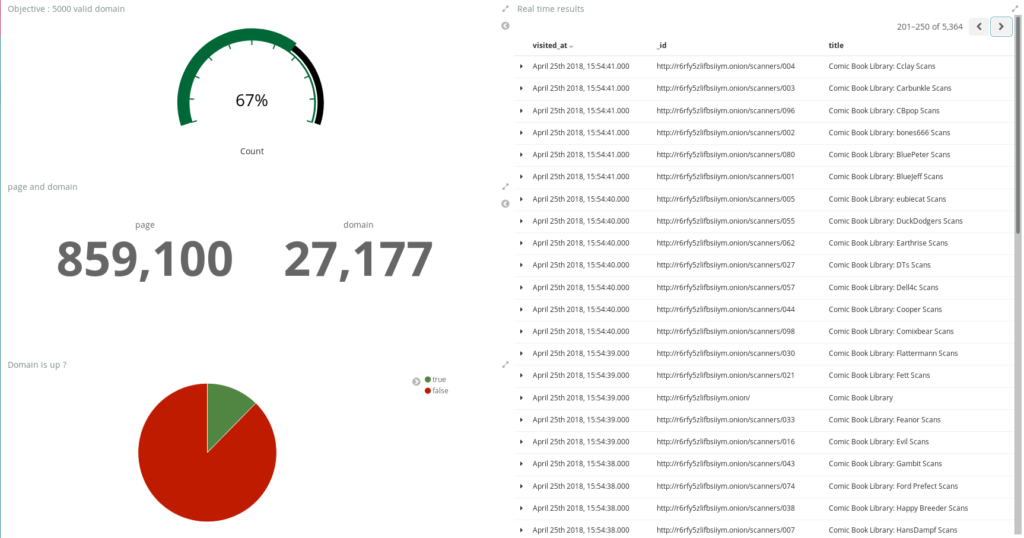
Finally, I did a dashboard to have better data visualization. We also see the latest crawled sites with the real-time results on the right side of the dashboard. Needless to say this dashboard made my project really popular among colleagues and management.
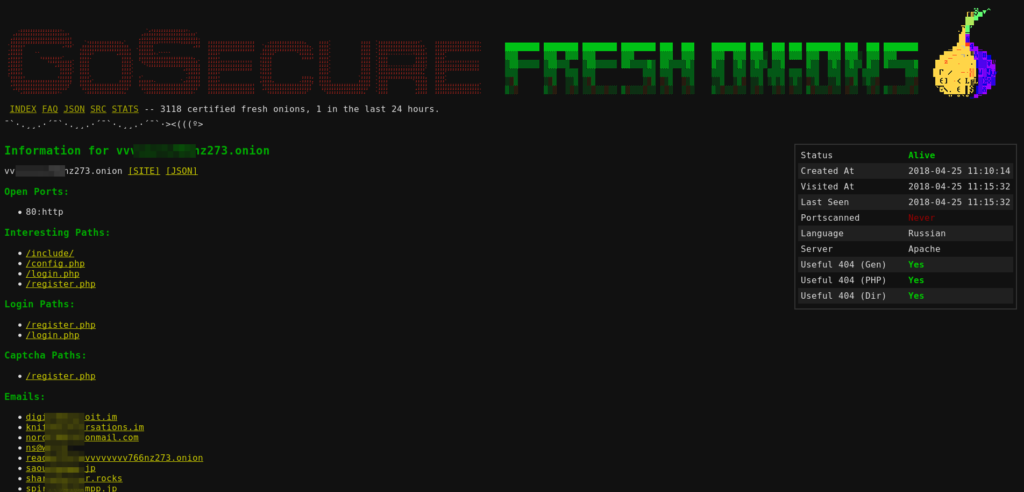
Here are some of the interesting lessons we learned here. First, given our initial seed .onion URLs (which might have important blind spots), we are able to store all the content of all darknet webpages that are not protected by a captcha or a login page and to fully index that data on a commodity server. Second, re-scanning our whole collection of domains takes around 3-4 days without any optimizations and by being gentle with the Tor network. Third, we collected a lot more bitcoin addresses than we anticipated.
GoSecure’s PasteHunter (Pastebin sites)
Similar to the first project, we were looking for something that already existed. The choice was pretty simple because we didn’t find a lot of existing projects that met our requirements. Compared to the first project, this one is completely different. In the first project, we are collecting all the information that we can find since we have the capacity to store it. In this second project, we didn’t expect it to scale so we are looking for a precise type of data instead and collecting just that. We are using the Pastebin web API, GitHub’s Gists and Dumpz to inspect all pasties. After some evaluation we settled on using the PasteHunter project because it uses Yara rules (a text/binary matching language commonly used in malware research). We also added our rules to find user/password leaks, database schemas, .onion URL, Bitcoin addresses, etc.
As of today, we gathered around 37 000 pastes that match at least with one of our Yara rules. Of course, it will continue to increase with time. The crawler works 24/7 and it waits 60 seconds after each pass on 200 links to be sure it doesn’t get throttled. The tool uses ElasticSearch to store all the data and it uses Kibana as an interactive Web interface. This project is pretty easy to install and maintain.

Conclusion
To conclude, we got satisfying results from both projects in a short amount of time. Both the Torscraper and PasteHunter initiatives have improved the capabilities of the organization to assess data leaks and will be useful for different parties (pentest, research, external partners, etc.). Working on these projects during my internship was a wonderful experience. Thanks to Masarah Clouston-Paquet and Olivier Bilodeau who supervised my internship. Both projects are available on GitHub: Freshonion’s Torscraper (our own fork) and Pastehunter.
This blog post has been written by Félix Lehoux who just completed his first undergraduate degree internship. We are proud of Félix’s work and we are glad he accepted the opportunity to share his research with the world through this blog post.
CAS D'UTILISATION
Cyberrisques
Mesures de sécurité basées sur les risques
Sociétés de financement par capitaux propres
Prendre des décisions éclairées
Sécurité des données sensibles
Protéger les informations sensibles
Conformité en matière de cybersécurité
Respecter les obligations réglementaires
Cyberassurance
Une stratégie précieuse de gestion des risques
Rançongiciels
Combattre les rançongiciels grâce à une sécurité innovante
Attaques de type « zero-day »
Arrêter les exploits de type « zero-day » grâce à une protection avancée
Consolider, évoluer et prospérer
Prenez de l'avance et gagnez la course avec la Plateforme GoSecure TitanMC.
24/7 MXDR
Détection et réponse sur les terminaux GoSecure TitanMC (EDR)
Antivirus de nouvelle génération GoSecure TitanMC (NGAV)
Détection et réponse sur le réseau GoSecure TitanMC (NDR)
Détection et réponse des boîtes de messagerie GoSecure TitanMC (IDR)
Intelligence GoSecure TitanMC